
|
|
|
|
|
|
|
|
University of Maryland, College Park University of Washington |
|
|
Neural Inverse Rendering of an Indoor Scene From a Single Image. We propose a self-supervised approach for inverse rendering. We jointly decompose an indoor scene image into albedo, surface normal and environment map lighting (top). Our method outperforms state-of-the-art approaches (bottom) that solve for only one of the scene attributes, i.e. albedo (Li et. al.), normal (Zhang et. al.) and lighting (Gardner et. al.). |
 |
Soumyadip Sengupta, Jinwei Gu, Kihwan Kim, Guilin Liu, David W. Jacobs, Jan Kautz. Neural Inverse Rendering of an Indoor Scene From a Single Image In ICCV 2019. |
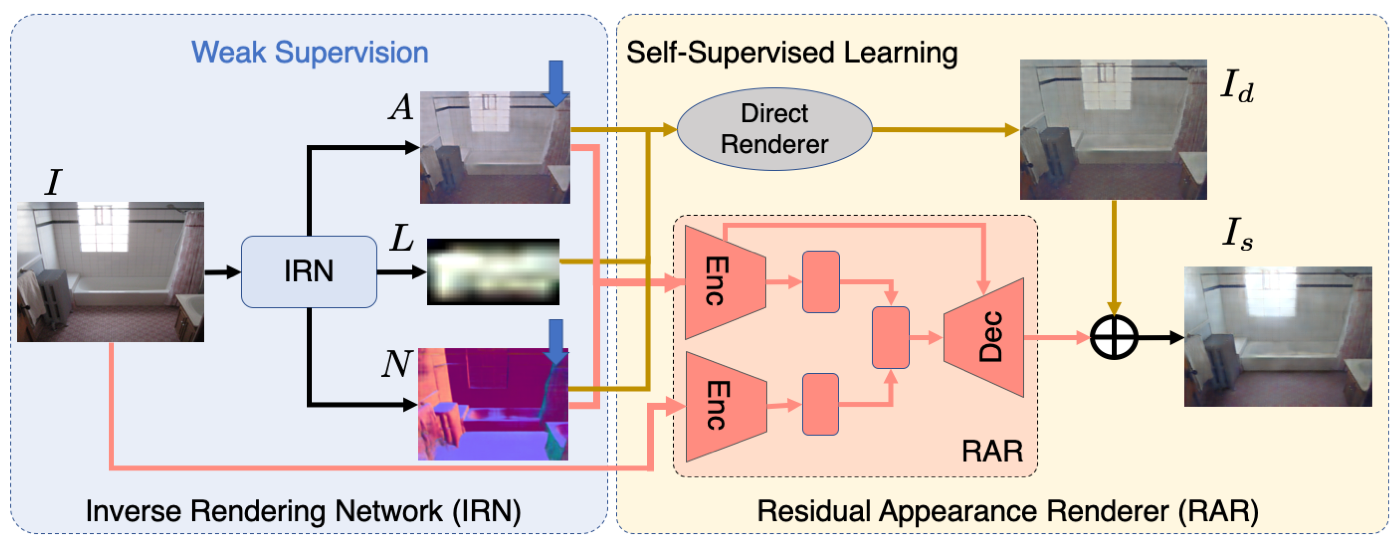
| Overview of our approach. Our Inverse Rendering Network (IRN) predicts albedo, normals and illumination map. We train on unlabeled real images using self-supervised reconstruction loss. Reconstruction loss consists of a closed-form Direct Renderer with no learnable parameters and the proposed Residual Appearance Renderer (RAR), which learns to predict complex appearance effects. |
|
|
|
|
 Comparison with Zhang et. al. |
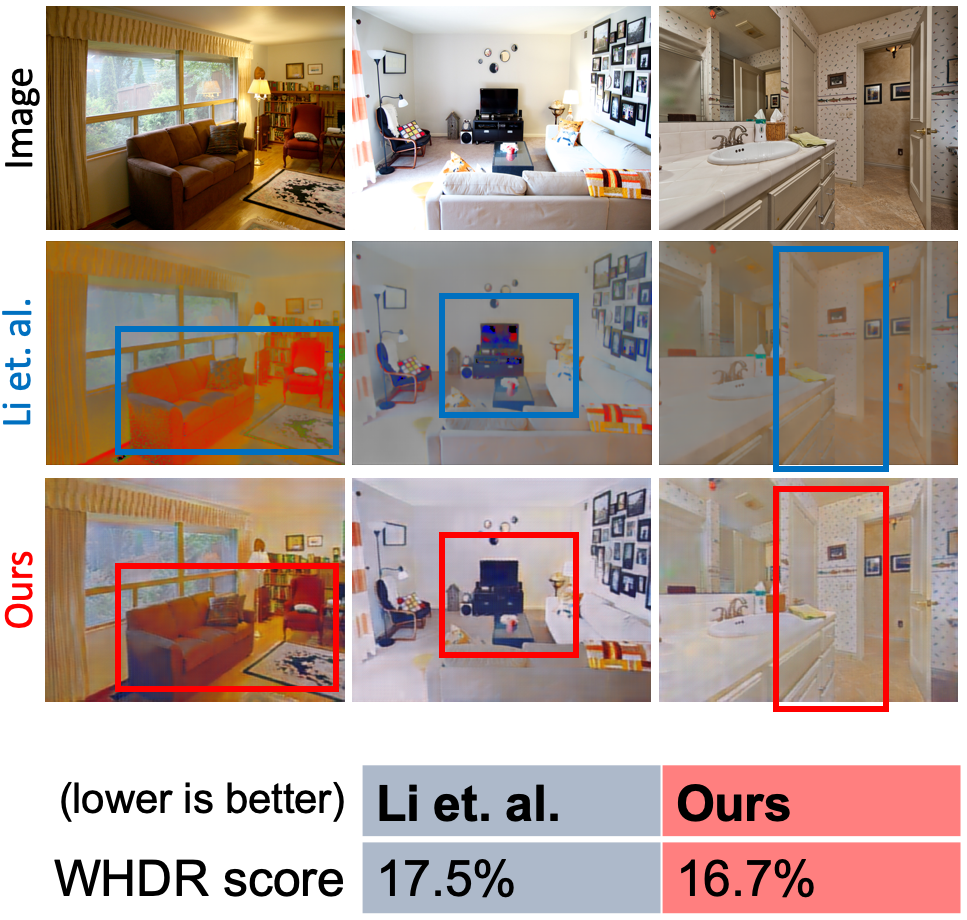 Comparison with Li et. al. |
|
|
|
|
 Comparison with Gardner et. al. |
 |

Acknowledgements |