|
|
|
|
|
|
University of California, Berkeley |
|
|
SfSNet: Learning Shape, Reflectance and Illuminance of Faces ‘in the wild’. We present SfSNet that learns from a combination of labeled synthetic and unlabeled real data to produce an accurate decomposition of an image into surface normals, albedo and lighting. Relit images are shown to highlight the accuracy of the decomposition. |
 |
Soumyadip Sengupta, Angjoo Kanazawa, Carlos D. Castillo, David W. Jacobs. SfSNet : Learning Shape, Reflectance and Illuminance of Faces ‘in the wild’ In CVPR 2018 (Spotlight). |
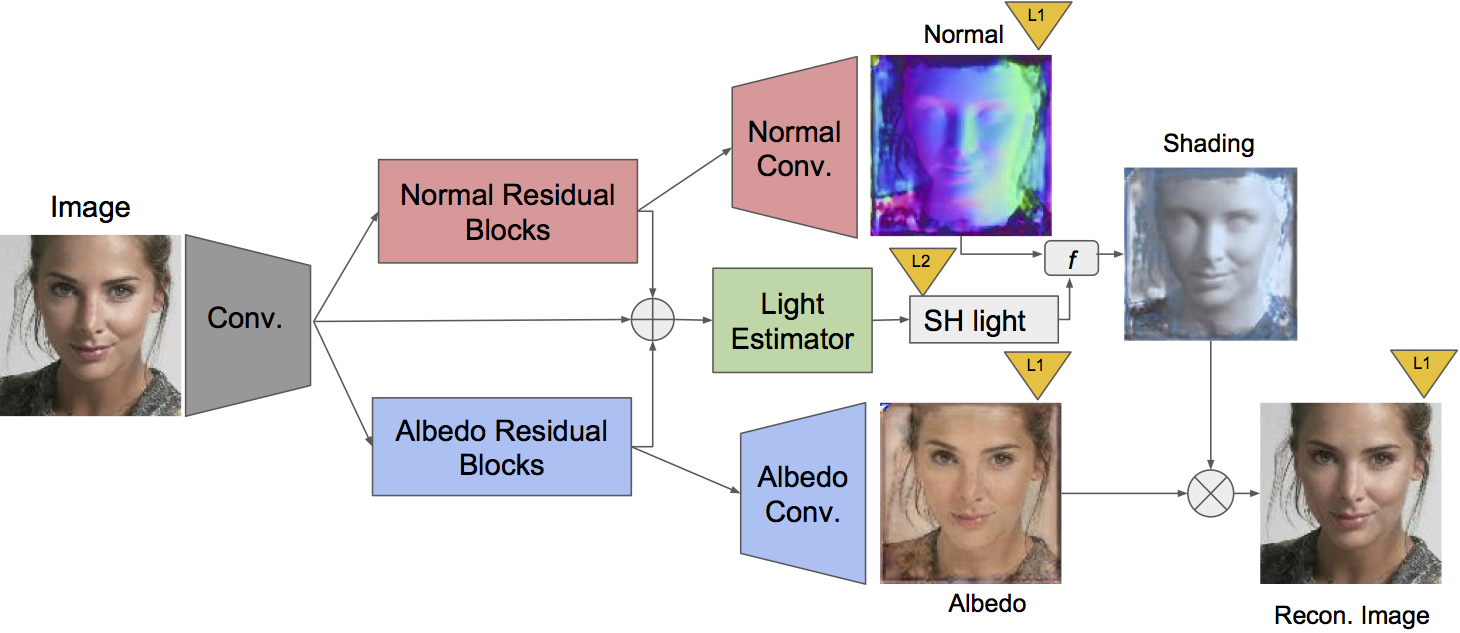
| Network Architecture. Our SfSNet consists of a novel decomposition architecture that uses residual blocks to produce normal and albedo features. They are further utilized along with image features to estimate lighting, inspired by a physical rendering model. f combines normal and lighting to produce shading. |
[GitHub] |
|
|
|
|
 SfSNet vs Neural Face on the data showcased by the authors. Note that the normals shown by SfSNet and Neural Face have reversed color codes due to different choices in the coordinate system. |
 SfSNet vs MoFA on the data provided by the authors of the paper. |

Acknowledgements |